Structured AI shifts the focus from generating tests faster to designing tests reliably.
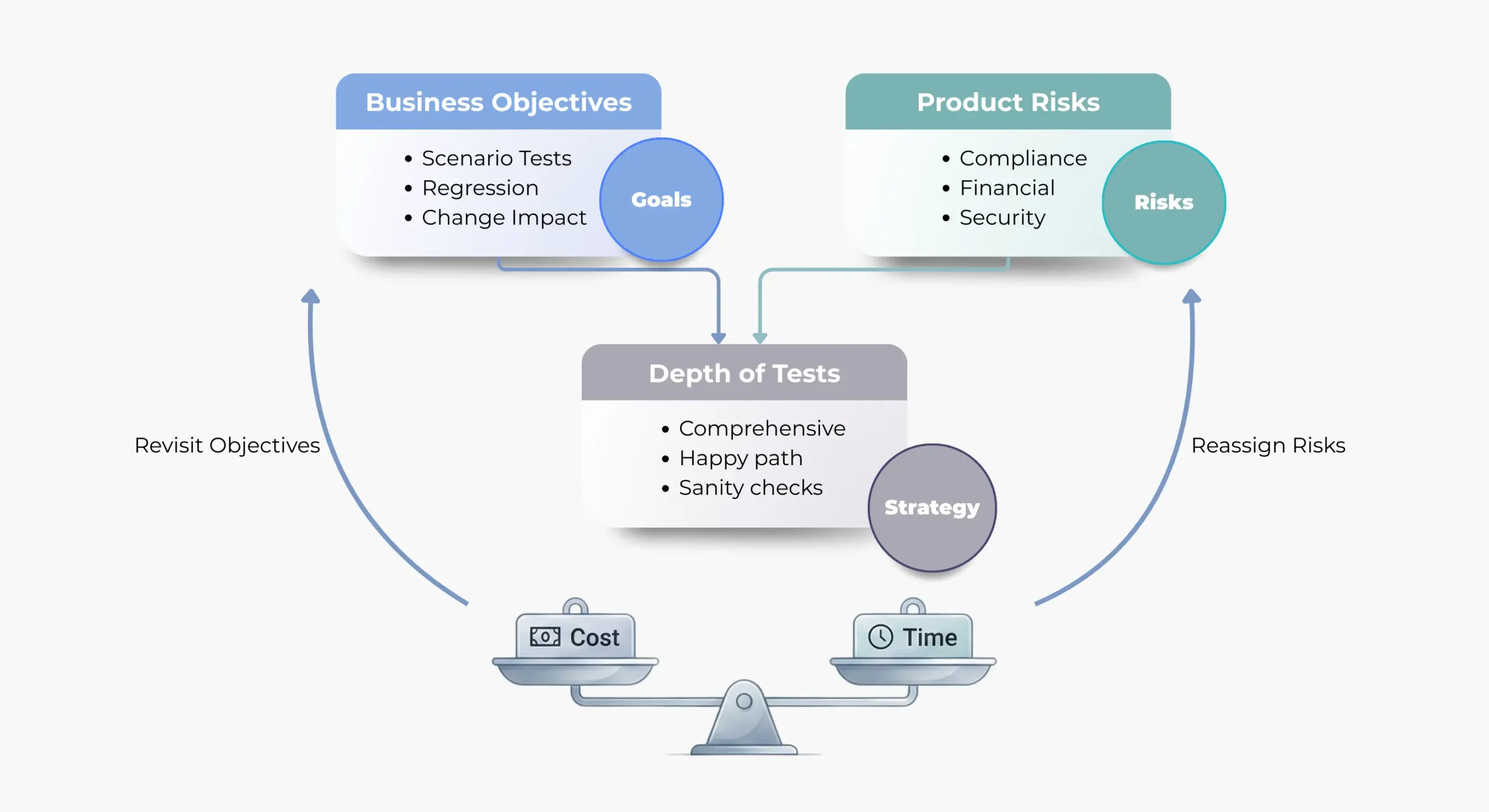
1. Methodology-Driven Authoring with Governance
Structured AI follows proven testing methodologies such as risk-based testing, TMap®, etc in defining:
- Test goals aligned to business risk
- Coverage rationale and prioritization
- Explicit test strategies and techniques
This ensures predictability, repeatability, and auditability in test design.
Example: In a Prop-Tech project using a custom-built AI solution aligned to risk-based methods, test depth was directly mapped to business impact. Teams achieved predictable coverage and a balanced trade-off between quality, time, and cost.
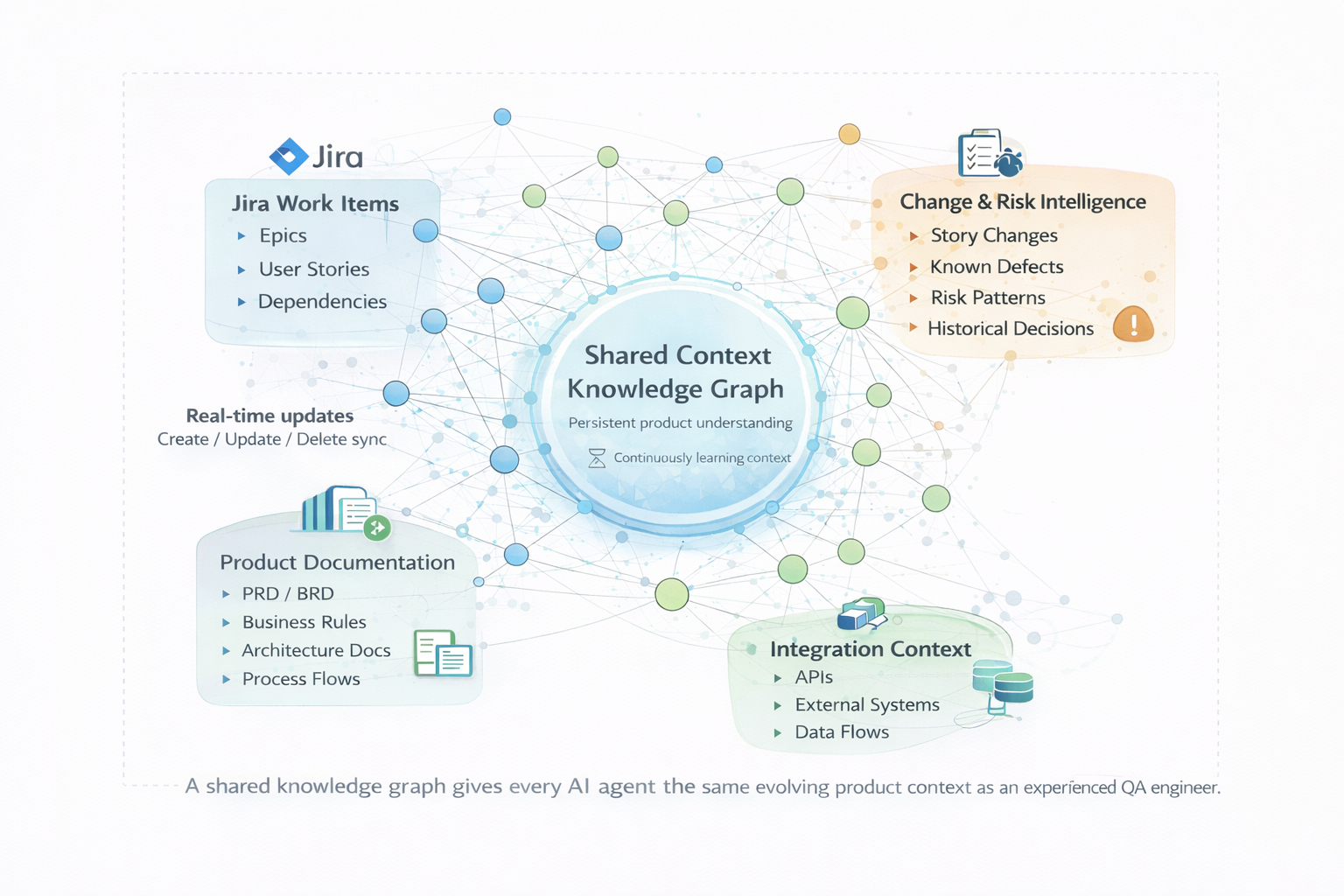
2. Context-Aware Test Generation
Instead of relying on a single prompt, structured AI uses a persistent knowledge layer comprising user stories, workflows, architecture diagrams, integrations, and prior changes.
This allows AI to generate tests with the same system-level understanding that experienced QA engineers rely on, improving coverage consistency and reducing downstream rework.
Example: In a large enterprise workflow and compliance platform, senior QA engineers relied heavily on institutional knowledge to design meaningful tests. Earlier AI-generated tests lacked this context. Once test authoring agents were made context-aware, AI began identifying downstream impacts and edge cases upfront, reducing rework and improving coverage consistency.
3. Transparent Test Strategy
Structured AI makes the test strategy visible by exposing:
- Risk-to-test-goal mappings
- Coverage maps and completeness scoring
- Test techniques applied and rationale
Teams can see what is being tested, why it matters, and what remains uncovered before execution begins.
Example: In a retail POS system, teams could trace every test case back to its risk, test goal, and chosen technique. This transparency improved review quality and strengthened release confidence.
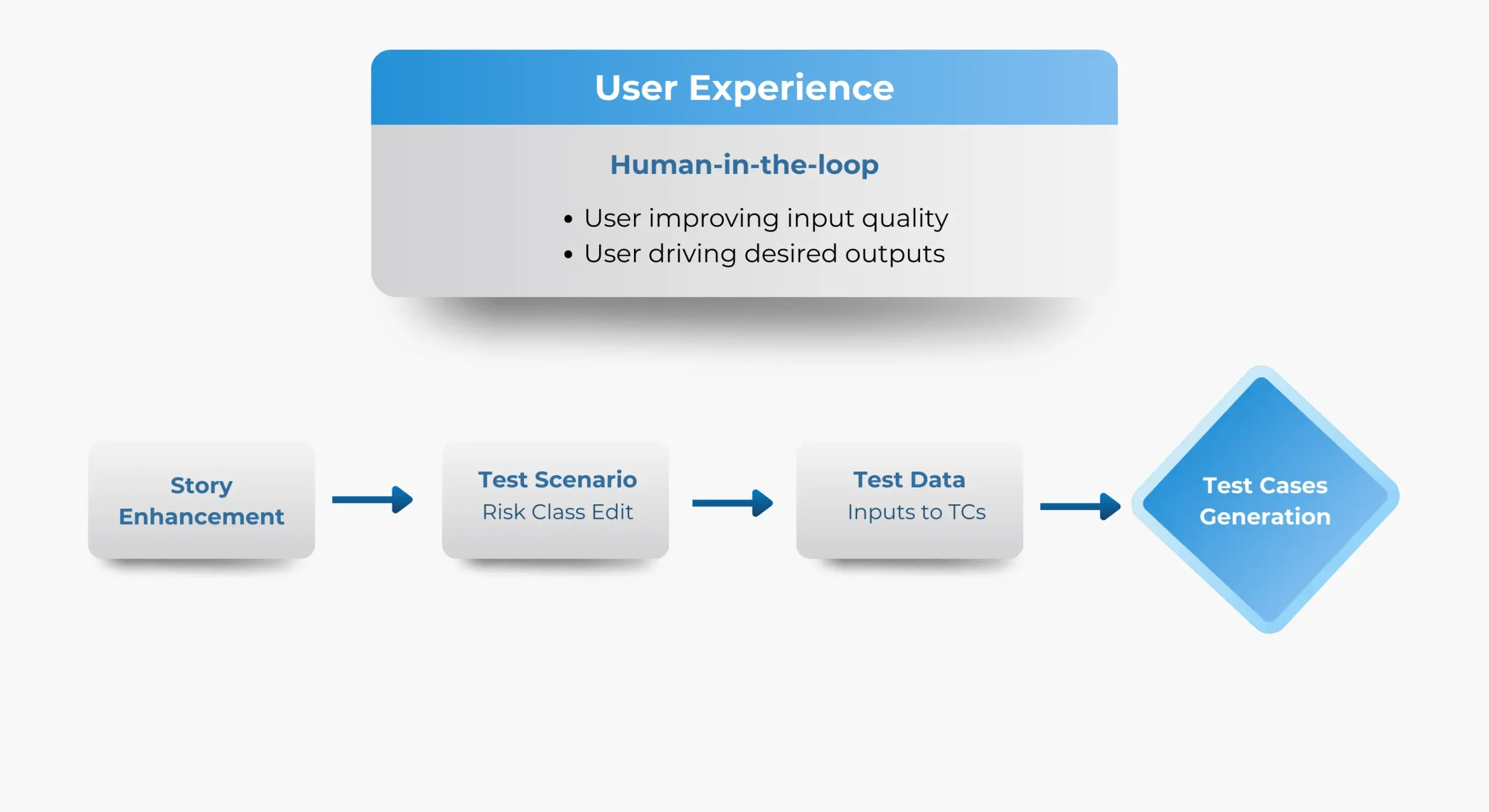
4. Human-in-the-Loop Control
AI accelerates test authoring, but humans retain ownership. QA engineers review, refine, and approve outputs, ensuring accountability while multiplying productivity.
AI acts as an assistant, not an autonomous decision-maker.
Example: In a large enterprise workflow and compliance platform engagement, testers adjusted risk severity for critical workflows before finalizing test suites. This human oversight improved confidence without slowing delivery.