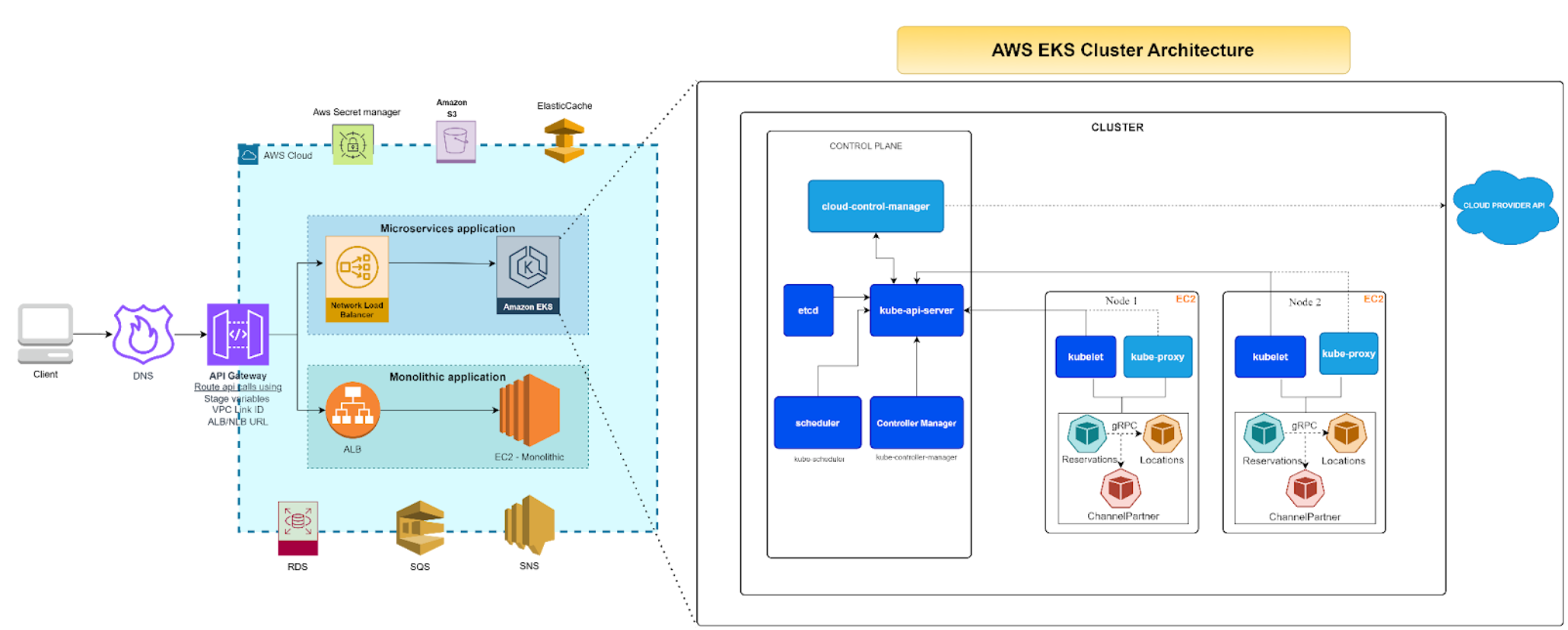
In this part 3 of the series, we will explore the different steps in the decision making process to identify an appropriate solution and create the migration plan.
To plan for the movement, we did the following:
Technology snapshot of existing application
| Backend Technology | NodeJs, ExpressJS deployed on provisioned VMs |
| UI | Angular 7 deployed on a proprietary cloud app delivery solution |
| ETL Jobs | Proprietary ETL solution |
| Data Integration/Client Systems | Node Red, Kafka based service |
| APIS | API Gateway + Developer portal |
- Study the current system and components in detail.
- Divide the product into modules that could be individually prioritized and completed.
- Identify the high-risk areas that need a proof of concept.
- Identify replacements for existing components and the resultant changes to the codebase.
- Create a roadmap with early integration points to verify successful completion of a module.
Proof of concepts
To gain confidence about the architecture, the following POCs were done upfront :- DB2 movement: Deployment of DB2 community edition in an AWS VM and move data from currently hosted DB2 to the AWS VM. This was a complex task since we did not have access to the backup of the database, nor was it simple to do it manually. To achieve this, we had to connect to the DB2 server as a remote catalog and take a backup of each table in IXF format. This backup was then restored on the AWS hosted DB2 server.
- Rewriting ETL processes: We evaluated using AWS Glue as a solution and then settled on building a custom solution using NodeJs and a set of stored procedures that did the job elegantly.
- Data ingestion: For data ingestion into the system, we ended up with testing a solution based on SNS and SQS queues. This enabled us to push data to one SNS topic and publish it to the production as well as the UAT environment simultaneously using multiple queue subscriptions.
- Developers: For the developers portal, we implemented AWS API gateway for enabling 3rd party access to our APIs. For the developer portal, we did a sample implementation of aws serverless developer portal that helps create the catalog of the APIs and provide access to consumers.
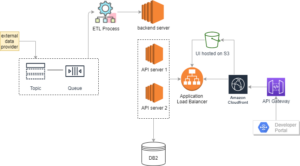
Solution Diagram
Solutions
| Component | Current | AWS |
| Database | DB2 (Hosted) | Production – DB2 image from Midvision |
| ETL Jobs | Proprietary | NodeJs/Database stored procedures |
| UI | Custom deployment framework | S3 bucket + CloudFront CDN |
| Third party integration | Kafka based service for ingesting data | SNS+SQS combination |
| Monitoring | Custom Framework/Self Hosted | Datadog/Cloudwatch |
Key benefits
- A more stable application with visibility into the state of the cloud servers and platforms through a single pane of glass.
- Greater than 50% reduction in the overall operational cost with around 25% increase in application performance and turnaround times.
- Deployment using terraform scripts and ability to scale up or scale down resources as needed.
- Control over database backups and recovery process.
- More control over ETL jobs.
- Cloud-agnostic architecture.