AI-native Product Management: How to Evaluate, Build, and Scale Trustworthy AI Products
- Yogesh Shelar
- May 4, 2026
Overview
TL;DR
Traditional product management, built for predictable software, breaks when applied to probabilistic AI products. Success requires adding a fourth core discipline—Evaluation—alongside Discovery, Delivery, and Outcomes. This means systematically measuring not just if features work on average, but if they behave reliably, safely, and build trust across all contexts and edge cases. Product leaders must shift from shipping static features to stewarding adaptive systems and prioritize managing variance and continuous risk.
The Shift to AI
Why Product Leadership Must Evolve-Without Abandoning Its Foundations
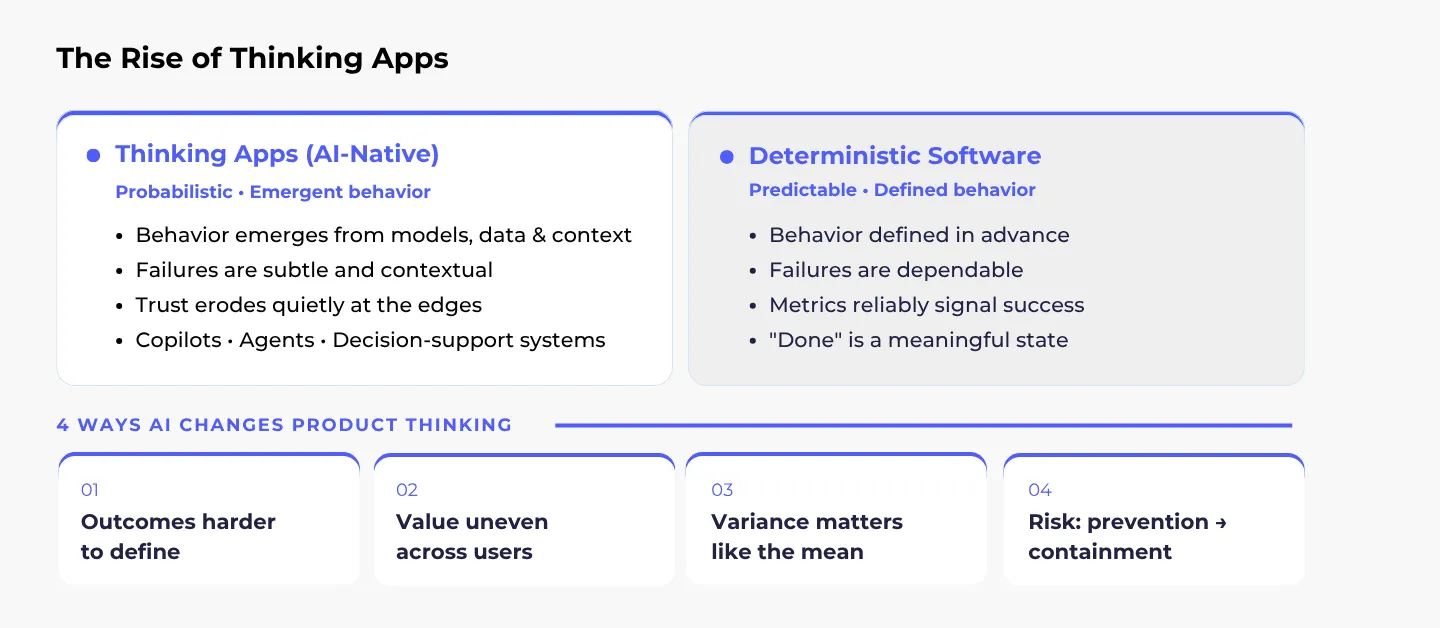
For most of our careers, product management has dealt with largely deterministic products. We define requirements, design interactions, ship features, and measure outcomes. When something goes wrong, we debug and fix it. Thinking apps break this mental model.
By “thinking apps,” I mean AI-native products where behavior is probabilistic, outcomes are non-deterministic, and value often emerges rather than being fully prescribed. Copilots that suggest actions, agents that take initiative, and decision-support systems that influence judgment do not just execute instructions. They reason, infer, and sometimes hallucinate.
In deterministic products, PMs typically focus on three core activities:
- Discovery: deciding what to build
- Delivery: actually building it
- Outcomes: measuring whether it worked
When metrics move in the right direction, we assume the product behaves as intended. In AI products, that assumption collapses. Metrics can look healthy while trust quietly erodes, because failures are often subtle, contextual, and easy to miss until they matter. A system may work well most of the time and still fail in ways that change how users relate to it.
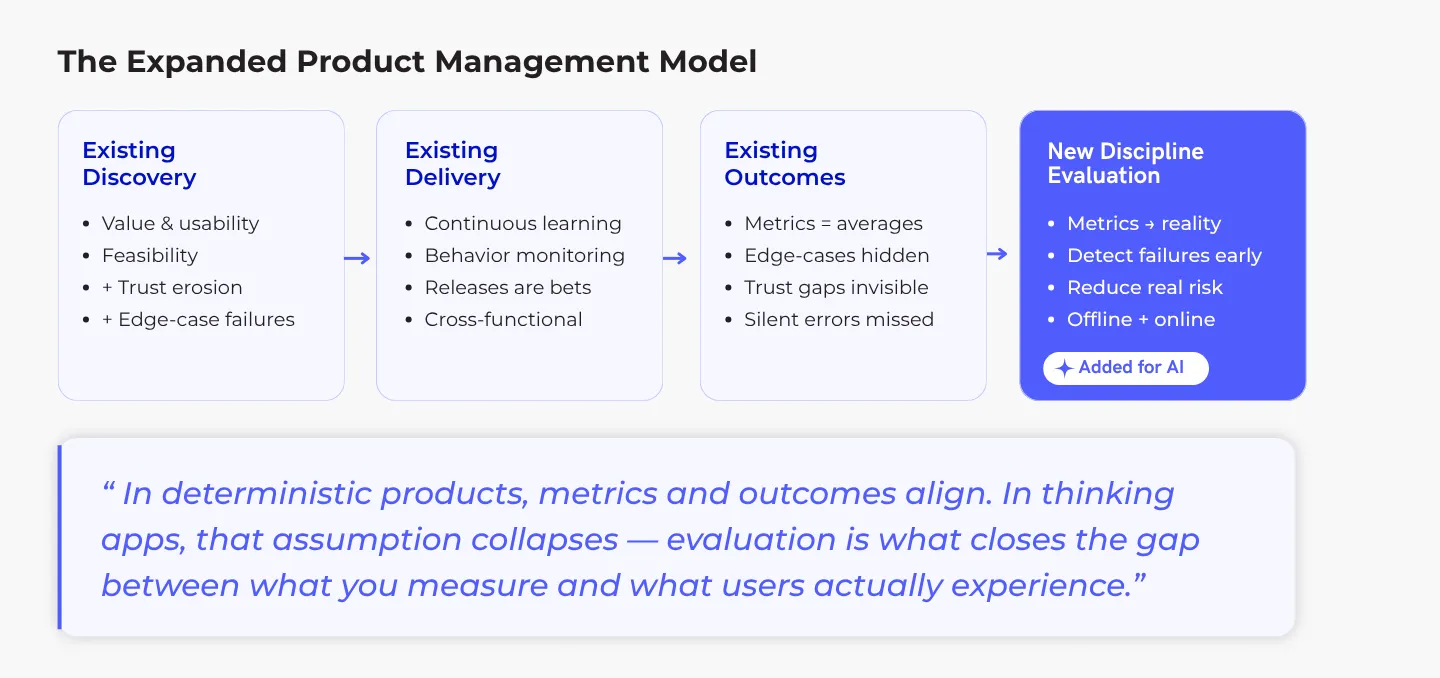
That is why AI-native products demand an additional discipline: evaluation. This is a structured way to understand whether the system is reliably producing the outcomes we actually care about, across the contexts that matter most. This article is about extending product management carefully, rigorously, and with humility to meet that reality.
Core Challenges
Modern Product Management Strains in Probabilistic Systems
Modern PM thinking rightly centers on outcomes over outputs. We frame problems, test assumptions, and prioritize opportunities based on evidence. That works beautifully when systems behave predictably. Probabilistic systems change the game in four important ways:
- Outcomes become harder to define precisely: Adoption or task completion can look healthy while subtle failures accumulate. A sales copilot that drafts convincing emails 90% of the time may still erode trust if the remaining 10% are confidently wrong.
- User value becomes uneven: Often in ways teams do not notice until trust slips. Different users, contexts, and edge cases experience wildly different qualities. The median user might be fine. The most important users-the ones operating under pressure-might not be.
- Prioritization changes: In AI systems, variance matters as much as the mean. A small improvement that reduces catastrophic failures may be more valuable than a large average-case gain.
- Risk management becomes continuous: You are no longer just asking, “Does this work?” You are asking, “Where can this fail, how badly, and how often are we willing to tolerate that?”
AI does not invalidate modern product management. It exposes where previous assumptions of predictability no longer apply.
Discovery & Delivery
Product Discovery in AI-native Systems
Product Discovery has always been about risk reduction: value, usability, feasibility, and viability. AI does not replace this; it adds new risk dimensions. AI product discovery is not just about whether users want a solution. It is about whether a probabilistic system can deliver that solution reliably enough to earn trust. Subtle model failures can derail even a highly desired feature, often in ways users do not immediately notice.
Subtle failures, overconfident wrong answers, and issues that only appear under rare conditions or repeated use can quietly erode the product, even when early user feedback looks positive. Discovery must anticipate not only what users want, but also how the system’s behavior interacts with trust, interpretation, and repeated use.
Effective discovery for thinking apps integrates:
- Early engagement with ML or data teams to understand feasibility boundaries.
- Hypotheses that account for trust, interpretability, and failure impact, not just task completion.
- Prototypes that explore error cases, edge behaviors, and rare but significant failure modes.
The goal remains the same: reduce risk before scaling, but the scope of risk has expanded. Discovery must probe both user needs and product behavior associated with the model, ensuring the system earns trust in real-world, unpredictable contexts.
Product Delivery in AI-native Systems
Delivering AI-native products requires a fundamental shift in mindset: from shipping static features to stewarding living, adaptive systems. Since a product’s behavior evolves continuously with data and model updates, each release becomes a probabilistic bet rather than a guaranteed improvement. Success, therefore, is no longer about achieving a final “done” state but about orchestrating ongoing learning and maintaining trust.
Shipping AI-native products means managing a fundamental change. You are no longer just delivering fixed features; you are operating living systems that learn and change over time. This makes every release more of a bet than a guarantee, as a tweak that helps one group of users might accidentally cause a problem for another.
Effective delivery requires:
- Continuous Recalibration: Monitor system behavior in real time and adjust models, data pipelines, or parameters before minor issues become major failures.
- Cross-functional ownership: Product, Engineering, and ML teams work jointly on release decisions.
- Instrumentation as part of the product: Observability is essential. Metrics, logs, and alerting help teams understand how behavior unfolds in real contexts.
- Behavior-focused quality goals: Success is not just “does it work?” but “does it behave reliably and safely across contexts?”
Shipping AI-native products is about orchestrating ongoing learning and trust maintenance and accepting that “done” is no longer a meaningful state. Teams that treat delivery as a continuous partnership between product, engineering, and data are the ones that avoid surprise failures while scaling AI responsibly.
Outcomes Gap
Product Outcomes: Why Metrics Alone Are Insufficient
In traditional deterministic products, measuring success is straightforward. Metrics tell the clear story. If a checkout success rate rises from 90% to 97%, you know the product improved.
But AI-native products complicate this. Because their outputs are probabilistic, good average metrics can hide real problems. A summarization tool might be highly accurate overall but still sometimes produce harmful content. A decision-support system could boost efficiency while quietly introducing bias.
This creates a dangerous gap between what your dashboard measures and what users actually experience. By the time a drop in trust shows up in your numbers, users have often already decided the system is not reliable.
That is why evaluation becomes a core product discipline. It is the essential bridge between raw metrics and real user outcomes. Done right, evaluation turns numbers on a dashboard into actionable insight about trust, safety, and genuine value.
Evaluation Engineering: Turning Uncertainty Into Action
Evaluation Framework
Evaluation engineering exists because there is a gap between your metrics and whether users actually trust the system. Its job is to help teams make good decisions even when outcomes are uncertain. Instead of just asking if the numbers look better, evaluation asks: where does the system break? How do those failures impact users? Do our changes actually reduce risk?
Unlike traditional software testing, evaluations for AI are directional and probabilistic by design. You are looking for signals and learning quickly, not chasing perfect, final answers. The goal is to reduce risk and learn fast, not to achieve false precision.
A Layered Way to Think About Evaluation
One practical way to organize your thinking is to use a layered model. This is not a rigid checklist, but a helpful mental model for finding where problems often hide.
1. The Component Layer (Functional Correctness)
This layer evaluates individual building blocks such as prompts, LLM outputs, RAG retrieval, tools, and agent logic. It ensures each component behaves correctly in isolation, with accurate retrieval, clear instructions, and valid tool calls before they are composed into larger workflows.
2. The Operational Layer (Efficiency and Economics)
Here, evaluation focuses on how efficiently the system runs in practice: token usage, latency, model selection, and cost-to-value tradeoffs. The goal is to ensure the system is not only correct, but also scalable, predictable, and economically viable in production.
3. The Memory and Metamorphics Layer (State and Resilience)
This layer tests how the system behaves over time and under variation. Does it remember context correctly across a conversation? If a user paraphrases a question, does it still understand? Using techniques like metamorphic testing, you check for consistency and robustness against real-world noise and changes.
4. The Black-Box System Layer (End-to-End Outcomes)
At the top layer, you evaluate the complete user experience. You treat the entire application as a black box and ask: does the multi-step workflow actually succeed? Is the outcome safe and useful? Does it solve the user’s real task? This confirms all the pieces come together to deliver genuine value.
It helps to think of evaluation not as one single test, but as a set of different lenses. Each lens gives you a unique way to examine your system’s behavior from a different angle.
Not every product needs deep focus on every layer. The real value of this model is in recognizing that failures in AI systems are rarely simple. By examining your system from these different depths, you can spot critical issues that simple averages or top-level metrics would miss completely.
Model Evaluation vs. Product Evaluation
A critical distinction is what you assess: the model’s capabilities, or the product’s real-world behavior and impact.
- Model evaluation answers capability questions: Is the system robust? Where does it fail?
- Product evaluation answers value questions: Does this create user value? Does it build or erode trust? What happens when it fails?
A high-performing model can still be a weak product if it fails when it matters most. Product evaluation ensures technical performance translates into real-world effectiveness. Strong products require both, but product evaluation must lead.
The Evaluation Stack in Practice
Evaluation manifests as a set of mechanisms that evolve over time:
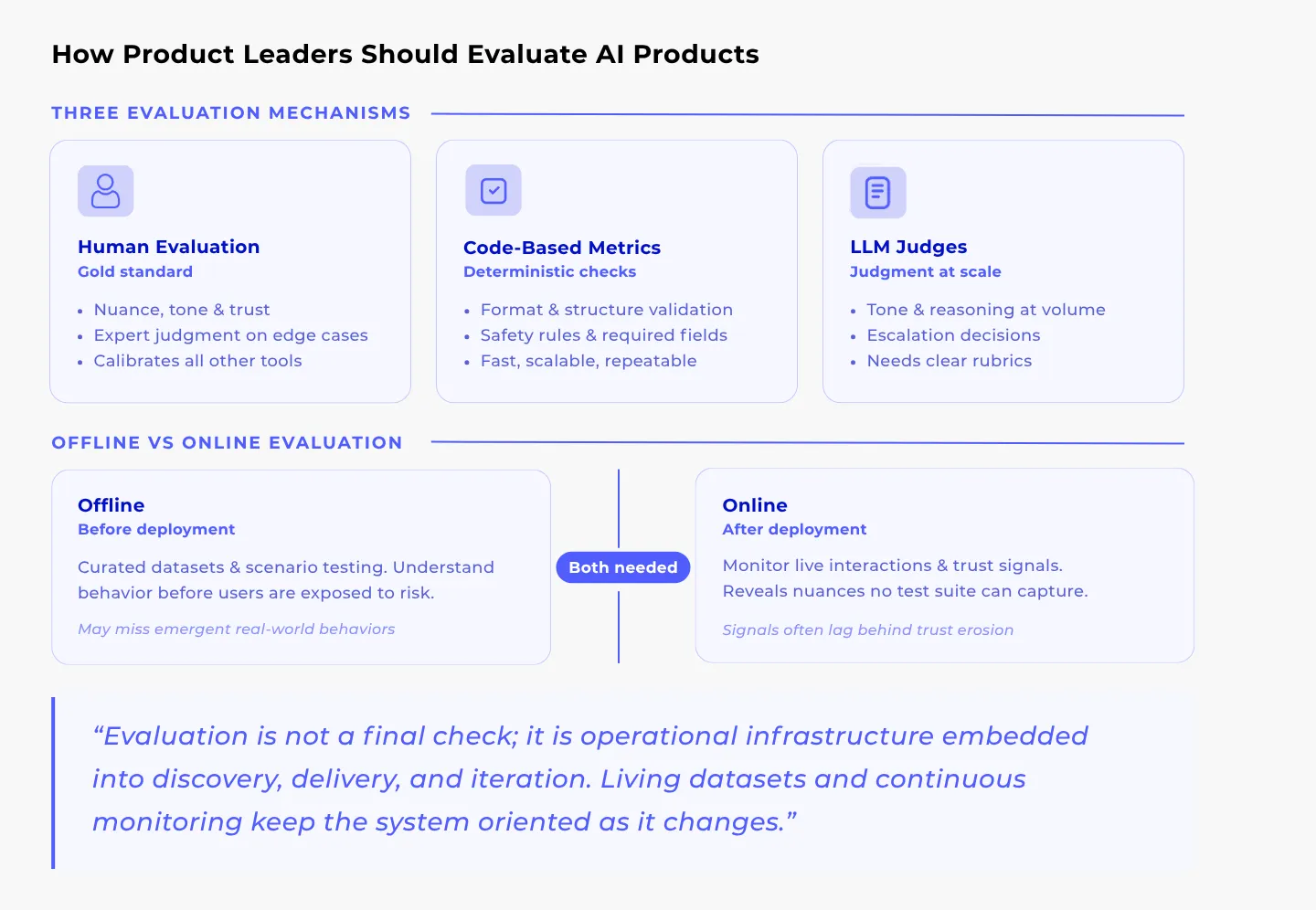
- Human Evaluation
Humans are essential for assessing nuance, tone, and empathy. They are the only way to calibrate “trustworthiness.” While expensive, human review is non-negotiable for high-stakes scenarios. - Code-Based Metrics
Fast, scalable checks for objective failures. Are JSONs formatted correctly? Are prohibited terms avoided? These “safety rails” catch mechanical errors so humans can focus on judgment. - LLM Judges
Using one model to grade another. LLM judges scale human-like reasoning across thousands of interactions. They are excellent for checking tone consistency and reasoning quality, provided they have clear rubrics. - Layered Integration
The strongest stacks combine the above: Humans for nuance, code for safety, and LLMs for scale. This ensures you catch both average performance and tail-risk failures. - Living Evaluation Assets
Static benchmarks give a false sense of security. Teams must maintain dynamic test sets and evolving rubrics that reflect how users actually use the tool, not how you imagined they would.
Organizational Implications for CPOs and CTOs
Thinking apps require new organizational habits.
- Cross-Functional Collaboration: PMs need technical intuition (probability/risk); Engineers need product judgment (user impact).
- Cultural Shifts: Reward learning velocity and risk containment, not just feature output. Treat safety as a feature.
- Redefining Success: KPIs must account for consistency and tail-risk, not just engagement.
What Product Leaders Should Do Differently Now
- Think in Layers: Combine humans, metrics, and LLMs for a holistic view.
- Treat Evaluation as Infrastructure: Build it into the core, don’t bolt it on.
- Prioritize Trust: Track signals of trust erosion, not just usage.
- Iterate Organizationally: Align incentives to safe experimentation.
- Invest in Living Assets: Keep datasets and rubrics alive.
- Guard Against Pitfalls: Never rely solely on A/B tests or averages.
Conclusion
Conclusion
Thinking apps do not invalidate modern product management-they expose where our instincts stop working. Deterministic habits fail when averages look fine but damage happens at the edges.
Evaluation is the discipline that connects intent to behavior. It does not replace discovery or delivery; it makes them viable in a world where software does not behave the same way twice.
“In a world of thinking software, product leadership is no longer about certainty-it is about earning trust under uncertainty.”
Still Treating AI Like Traditional Software?
Discover how Indexnine helps product teams build structured evaluation systems that go beyond averages, so your AI behaves reliably in the moments that matter.