In the earlier blog post of this series, we had seen a general overview of serverless computing with AWS. In this part, we will look at configuring a Lambda function and follow up with an architecture diagram of an application that performs real time processing of data coming in from multiple sources.
Lambda Configuration – tips and good practices
There are various items that require configuration when setting up a Lambda function. Let’s look at some of these.
1. Triggers
Triggers are used to start the execution of a Lambda function (similar to the OS calling the main() function). Some the various AWS services that can trigger a Lambda function are:
- Amazon S3 [e.g. File upload]
- Amazon DynamoDB [e.g. Record insertion]
- Amazon Kinesis Data Streams [e.g. Data uploaded to stream]
- Amazon Simple Queue Service [e.g. Message queued in SQS]
- Other Event Sources: You can build your own custom event source to invoke a Lambda function [e.g. An API call to your webservice]
Most AWS services can trigger lambda functions, the above list is not comprehensive. To review the full list, go here.
TIP: Test events can be created as triggers. These are useful to test your code without actually having to set up the actual trigger service during the initial development phase, or when you are trying out a POC.
2. Function Code
TIP: Although you can upload your jar/code directly here, it is good to go with AWS’s recommendation of uploading the jar to S3 if it is larger than 10 Mb. It is much faster.
3. Environment Variables
TIP: Use these for items that you would like to keep configurable. In a regular server these are the values that you would typically keep in a yml, cfg or properties file where they are likely to change for different setups. You would change these files and restart the server. The same is achieved in Lambda through use of these environment variables. These are accessible in the code by functions used to access environment variables. Examples of such items would be S3 bucket name, ElasticCache endpoint and port, SQS queue names, SNS topic names, etc.
4. Execution Role
This is an IAM role that has the permissions required by this Lambda.
GOOD PRACTICE: It is best to create a separate IAM role for your Lambda functions. You can start with a basic role. As and when you run into errors when trying to access AWS resources, you can add the required specific permissions to this role for those AWS resources. This way you can make sure that the role does not have access to anything other than what the Lambda code needs.
5. Memory/Timeout
You can configure the memory required by your code here. Note that this directly affects the CPU power that is allocated for your Lambda. This value has a direct impact on cost, and tuning this is a challenge as we shall see in the next part of this blog series.
The maximum timeout allowed for a Lambda execution is 5 minutes. Do make sure that your code does not take longer than this to execute, or you will get timeout errors that can build up the backlog of events.
6. Network
When a Lambda is created, the default VPC is used.
GOOD PRACTICE: It is best to create your own VPC with private and public subnets as recommended by AWS here: https://docs.aws.amazon.com/AmazonVPC/latest/UserGuide/VPC_Scenario2.html. Use this VPC for your Lambda. Then make sure that your Lambda functions are executed within the private subnets. The security group should also be configured specifically for these private subnets.
TIP: In case you have more stringent security requirements where you need dedicated hardware, then some more setup is required as AWS currently does not support execution of Lambdas in dedicated tenancy VPCs. They do have a workaround where you can peer your regular VPC running the Lambda to a dedicated tenancy VPC. This is described here: https://aws.amazon.com/premiumsupport/knowledge-center/lambda-dedicated-vpc.
7. Error Handling
Lambda allows you to configure dead letter queues in the case of failures. This can be either SNS or SQS. AWS directs events that cannot be processed to the specified resource.
TIP: Do set this up and examine it regularly. It lets you catch errors that you may have missed handling in your code. You can also use the same DLQ in your code to write out the errors that may get lost in the logs.
We will discuss more about the challenges related to error handling in the next installment of this series.
8. Concurrency
AWS gives you a concurrency limit of 1000 for your account. This means that at a time, a 1000 parallel Lambdas can be running in your account. (The same or different ones.) This parameter is used to limit the concurrency of a particular Lambda to a specific number.
TIP: Use this to limit the number of parallel executions of a particular Lambda to slow it down to keep pace with slower downstream processing components in your architecture. The exact number will depend on the type of computation and capacity available downstream to handle processing.
TIP: Use this if you are seeing throttling of any resource you may be polling.
TIP: Set this to 1 for cases where you want to make sure that simultaneous processing should be avoided. Example: If the trigger is S3, during bulk creation/deletion of files, the Lambda will get triggered simultaneously. If the files being processed are interdependent on each other, we can avoid simultaneous processing of these files by preventing concurrent executions of this Lambda function. Setting this value to 1 will solve such issues.
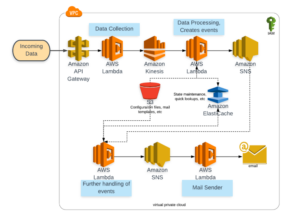
Architecture Diagram – Real-time data processing
The following diagram is a reference architecture for a real-time processing system.
Consider an application with the following main tasks:
- Collect data from incoming devices, write it to storage.
- Process the incoming data and test against rules to generate events based on incoming data.
- Send event for further processing, e.g. send out emails.
Here is a reference architecture diagram: