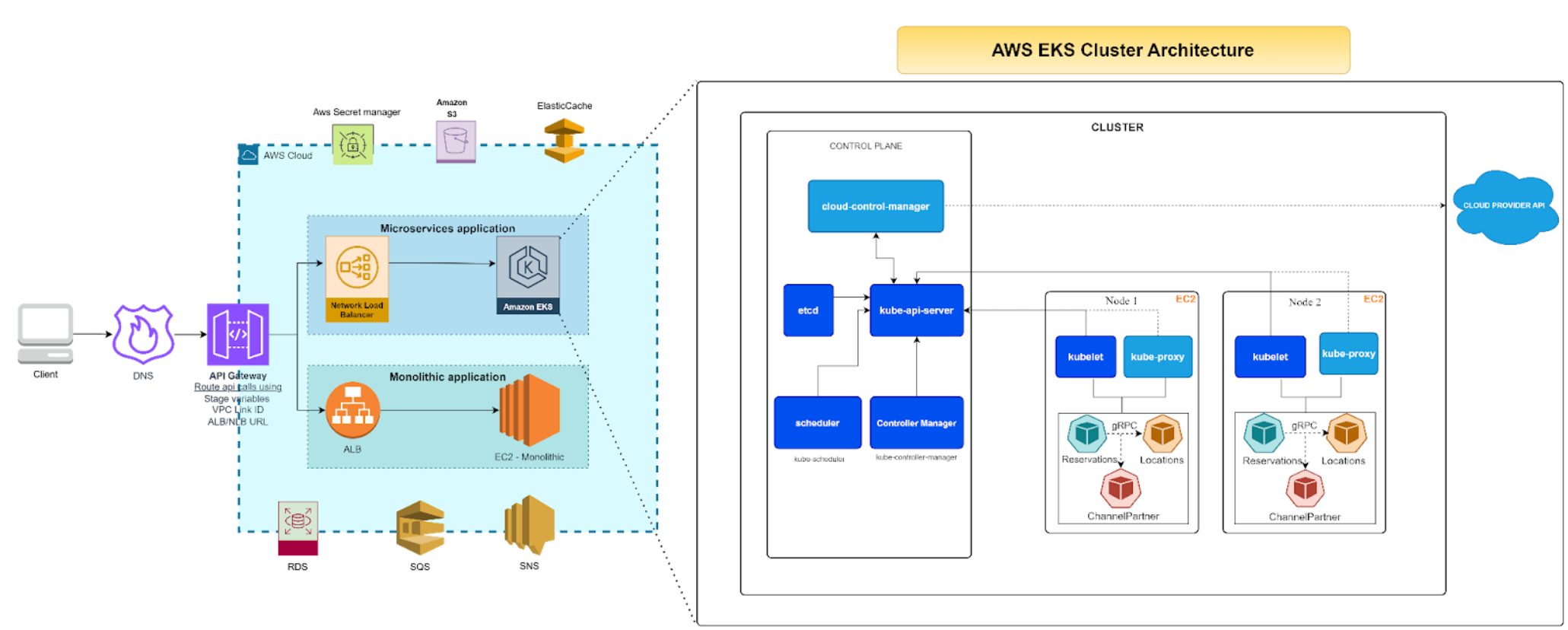
Testing LLMs
Large Language Models (LLMs) have become integral to various industries, revolutionising AI-driven operations. Their ability to generate human-like text, understand context, and perform complex tasks has made them invaluable across numerous applications. However, this power comes with significant responsibilities and risks:- Accuracy and Reliability: LLMs can sometimes produce incorrect or inconsistent information, which can be critical in healthcare or finance.
- Ethical Concerns: There’s a risk of bias, discrimination, or inappropriate content generation. This happens due to input data quality and drift in training data sets. It’s important to detect this early and build ethical checks into the development pipeline.
- Performance Variability: LLMs may perform inconsistently across different domains or types of queries.
- Security Vulnerabilities: LLMs can be susceptible to adversarial attacks or data leakage like any complex system. Prompt injection, Denial of service and other attacks can be carried out against insecure systems that rely on LLMs.
- Integration Challenges: Ensuring seamless operation with other systems and APIs is crucial for real-world applications.
LLM Testing Metrics
To address the multifaceted challenges of LLM, evaluation, employing an agentic testing workflow employs a range of testing types, with each agent playing a specific role in the process:- Functional Testing: Assesses the LLM’s ability to perform specified tasks accurately and consistently. This involves executing specific prompts and comparing outputs against expected benchmarks to identify errors or inconsistencies.
- Performance Testing: Measures response time, throughput, and resource utilisation under various loads. This includes stress tests to evaluate the LLM’s efficiency and responsiveness under different conditions.
- Domain-Specific Testing: Evaluates the LLM’s proficiency in specialized fields (e.g., medical, legal, technical). Specialized prompts assess domain expertise, with outputs compared against field-specific benchmarks.
- User Experience Testing: Analyzes the LLM’s responses from an end-user perspective, focusing on clarity, helpfulness, and overall satisfaction. This involves gathering feedback and evaluating usability metrics.
- Integration Testing: Verifies the LLM’s compatibility with other systems and APIs. This process ensures seamless interoperability by analyzing outputs and interactions with external systems including handling errors gracefully.
- Security Testing: Identifies potential vulnerabilities and assesses resistance to adversarial attacks. This involves designing and executing scenarios that test the LLM’s resilience to potential threats or data leaks. Critical testing involves the possibility of prompt injection attacks, especially when exposed by an API to the external world.
- Ethical and Bias Testing: Evaluates outputs for potential biases and adherence to ethical guidelines. This crucial step involves developing prompts to uncover biases and ensure responsible AI practices.
Agentic workflow to test LLMs
We have developed an innovative agentic workflow to execute comprehensive and efficient LLM testing. This approach utilizes multiple specialized agents working in concert, each focusing on specific aspects of LLM evaluation.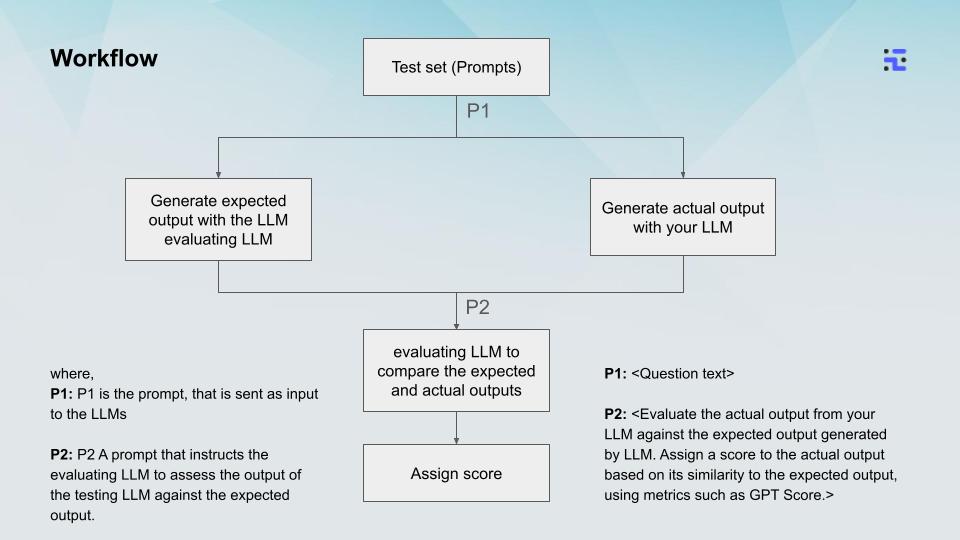
Key Components of the Agentic Workflow:
- Prompt Design Agent: Responsible for curating and managing a diverse set of test prompts (P1) that cover various scenarios and use cases.
- Benchmark Generation Agent: Utilizes an evaluator LLM to generate expected outputs for each test prompt.
- LLM Execution Agent: Runs the test prompts through the LLM being tested to produce actual outputs.
- Comparison and Evaluation Agent: Compares the expected and actual outputs using advanced natural language processing techniques, including GPT-based scoring.
- Scoring and Reporting Agent: Assigns final scores based on the evaluation results and generates detailed reports.
- Human-in-the-loop execution: To improve confidence in the agentic testing workflow, design and execute a human-in-the-loop strategy to audit test execution.
Workflow Process:
- Prompt Preparation: The Prompt Design Agent prepares a comprehensive set of test prompts (P1).
- Parallel Execution:
- The Benchmark Generation Agent uses an evaluator LLM to create benchmark responses
- Simultaneously, the LLM Execution Agent runs the same prompts through the LLM being tested.
- Output Evaluation: The Comparison and Evaluation Agent, guided by a specific evaluation prompt (P2), compares the expected and actual outputs using GPT-score or similar metrics.
- Scoring: The Scoring and Reporting Agent assigns a final score to the tested LLM based on the evaluation results.
- Insight Generation: Results are compiled and analyzed to provide insights into the LLM’s performance across various types of prompts and tasks.
Key Advantages:
- Leverages LLMs themselves for nuanced evaluation, capturing subtleties that traditional metrics might miss
- Allows for dynamic and context-aware testing, adapting to the complexities of natural language.
- Provides a standardized yet flexible framework for consistent LLM evaluation.
- Enables automated testing at scale, processing large volumes of diverse prompts efficiently.
- Offers detailed insights into LLM performance across different types of tasks and domains.